배열의 불편함
- 요소들의 자료형이 같아야함
- 많은 양의 데이터를 처리하기에 적합하다. 그러나 배열에는 자료 형이 같아야하고, 배열의 크기를 미리 정해야 하므로 용량이 부족하거나 혹은 낭비가 되는 경우가 있다.
- 중간 데이터를 삭제 및 추가하는 것이 번거로움
배열의 불편함을 해소하기 위해 JDK 14 부터 추가된 새로운 개념 : Java의 컬렉션 프레임워크(동적인 배열)
- 그래서 자바에서는 이러한 배열의 단점을 보완하기 위하여 동적인 배열 즉, 컬렉션 프레임워크를 만들어두었다.
- Interface들이므로 객체를 생성할 수 없고 implements 하여 사용해야 한다.
- 다양한 자료형도 담을 수 있다.
- 사이즈를 유연하게 조절할 수 있다.
- java.util에 각각의 이름으로 존재한다.
- 자바는 타입을 제한하기를 원해서 경고창이 뜬다.(타입 한정<타입>) 안 써도 컴파일은 된다.
- 기본자료형이 아닌 객체 자료형만 상대한다. (객체화).
- Auto boxing : 단, 요새는 자동으로 알아서 담아준다. 이것을 오토 박싱이라고 한다.
- 랩핑 클래스 : 옛날 자바처럼 rapping 해주는 객체를 만들어주는 클래스가 있었다.
- int 는 Integer 등.
제네릭(= 요소 타입 제한)
- 막상 요소들을 처리하려면 모든 타입들이 많아서 처리가 번거로워지기 시작함(타입마다 if 문을 걸어야 하는 단점이 있음)
- 가능하면 범위 자체를 한정하고 쓰자는 말이 나오기 시작함
- ArrayList list = new ArrayList() 와 같이 리스트를 생성하면 리스트에 온갖 자료형을 담을 수 있다. 처음에는 이것이 좋은 것이 아니다라는 것을 느끼게 된다. 만약 리스트에 Person 도 담고 Shape 도 담고, 또 , Employee 도 담고... 등 이렇게 되었을 때, 리스트에 담긴 데이터의 수 만큼 반복하여 결국은 그 요소에 따라 일처리를 시켜야 하는데, 각각 자료형이 다르면 일일히 instanceof 연산자로 타입을 물어보고 형변환한 후에 해당 클래스에 메소드를 호출해야 하는 것은 상당히 번거로운 일이다. 가능하면 Object 보다는 내가 만든 클래스의 상속관계에 범위를 제한하도록 권장한다. 즉, 리스트에 담는 자료형을 제한하도록 한다. 이것을 제네릭이라고 한다.
- ArrayList<Person> list = new ArrayList<Person>();
- Person 이 아니면 error를 발생시킨다.
- <범위 제한할 타입>
- 이렇게 리스트를 만들어두면 리스트에는 Person의 객체만 담을 수 있으며, 만약 Person의 후손이 있다면 Person의 후손 또한 담을 수 있다.
Set : 데이터의 중복을 허용하지 않는다.
- 타입을 제한하지 않는 한, 어떤 데이터도 담을 수 있다.
- 중복되는 것을 자동으로 없애준다.
- add () : object 를 Set에 추가하고, 성공적으로 담으면 true, object 중복 등으로 담기 실패하면 false 를 담아준다.
- size() : Set 의 데이터가 몇 개 담겨있는지 알려준다.
//다음의 인터페이스를 상속 받아 만들어졌다.
//All Superinterfaces Collection<E>, Iterable<E>
interface Set extends Collection, Iterable{
//Set 내용
}
//Set을 상속받아 만들어진 인터페이스
//All Known Subinterfaces: NavigableSet<E>, SortedSet<E>
interface NavigableSet extends Set{
}
interface SortedSet extends Set{
}
//Set을 상속받아 만들어진 클래스들
//All Known Implementing Classes:
AbstractSet, ConcurrentHashMap.KeySetView, ConcurrentSkipListSet, CopyOnWriteArraySet, EnumSet, HashSet, JobStateReasons, LinkedHashSet, TreeSet
class HeshSet implements Set{}
class LinkedHashSet implements Set{}
class TreeSet implements Set{}- Set으로 만들어진 클래스
- HashSet : 내가 입력한 순서를 유지하지 않는다.
- LinkedHashSet : 내가 입력한 순서를 유지한다.
- TreeSet : 입력한 데이터를 정렬, sort 해준다. 문자열이면 문자 순, 숫자이면 오름차순. 단, 문자열과 숫자를 혼용해서 넣으면 서로 비교할 수 없으므로 컴파일 에러가 난다.
package com.kosta.exam02;
import java.util.HashSet;
import java.util.Set;
public class HashSetTest {
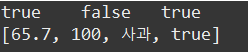
public static void main(String[] args) {
Set data = new HashSet();
boolean chk1, chk2, chk3, chk4, chk5;
chk1 = data.add(new Integer(100));
chk2 = data.add(100); //auto Boxing;
chk3 = data.add("사과");
chk4 = data.add("65.7");
chk5 = data.add(true);
System.out.println(chk1 +"\t" + chk2 + "\t"+ chk5);
System.out.println(data);
}
}
package com.kosta.exam03;
import java.util.LinkedHashSet;
import java.util.Set;
public class LinkedHashSetTest {
public static void main(String[] args) {
Set data = new LinkedHashSet();
boolean chk1, chk2, chk3, chk4, chk5;
chk1 = data.add(new Integer(100));
chk2 = data.add(100); //auto Boxing;
chk3 = data.add("사과");
chk4 = data.add("65.7");
chk5 = data.add(true);
System.out.println(chk1 +"\t" + chk2 + "\t"+ chk5);
System.out.println(data);
}
}

package com.kosta.exam04;
import java.util.Set;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
Set data = new TreeSet();
Set data2 = new TreeSet();
boolean chk1, chk2, chk3, chk4, chk5, chk6;
chk1 = data.add(100);
chk2 = data.add(100); //auto Boxing;
chk3 = data.add(436);
chk4 = data.add(24);
chk5 = data.add(18);
data2.add("앎");
data2.add("가나");
data2.add("사과");
data2.add("마름");
//System.out.println(chk1 +"\t" + chk2 + "\t"+ chk5 + "\t"+ chk6);
System.out.println(data);
System.out.println(data2);
}
}
List : 데이터의 중복을 허용한다.
- List.get(index) : 해당 인덱스 값을 가져온다. 단, List 는 여러자료형이 올 수 있기 때문에 가져온 값의 해당 자료형으로 캐스팅해줘야 해당 자료형의 변수에 값을 담을 수 있다.
- remove(Object o): 해당 index또는 object 를 이용하여 객체를 삭제한다.
- List 로 만들어진 Class
- ArrayList와 LinkedList의 사용법은 같은데, 내부 방식은 다르다.
- ArrayList : 자바의 컬럭션 중에서 가장 많이 사용된다.
- LinkedList: 데이터의 중간에 추가 삭제가 빈번한 경우에 사용하면ArrayList 보다는 더 효율적이다
Type Parameters:
E - the type of elements in this list
All Superinterfaces:
Collection<E>, Iterable<E>
All Known Implementing Classes:
AbstractList, AbstractSequentialList, ArrayList, AttributeList, CopyOnWriteArrayList, LinkedList, RoleList, RoleUnresolvedList, Stack, Vector
Map : key 와 value 가 한 쌍으로 이루어진 자료구조
- 인덱스 대신에 key 에 의해 데이터에 접근하는 방식
- 사전 자료형이라고도 한다.
package com.kosta.exam04;
import java.util.HashMap;
import java.util.Map;
public class HashMapTest {
public static void main(String[] args) {
Map <String, String> data = new HashMap<String, String>();
data.put("name", "홍길동");
data.put("addr", "서울시 종로구 종로 1가");
data.put("phone", "010-1111-1111");
String addr = data.get("addr");
System.out.println(addr);
System.out.println(data.get("phone"));
}
}
'Kosta DevOps 과정 280기 > Java' 카테고리의 다른 글
| 파일 입출력 (0) | 2024.05.24 |
|---|---|
| 난수 (0) | 2024.05.23 |
| final 키워드가 올 수 있는 곳 (0) | 2024.05.23 |
| 다형성(polymarphism) (0) | 2024.05.20 |
| 접근명시자 정리 (0) | 2024.05.20 |
